事業内容
私たちの事業領域
- 登記簿謄本解析システム
導入サービス 
-
不動産登記情報を規則性のあるテキストデータに変換するシステムを導入致します。
契約書等の書類への転記やチェックなど自動化の実現や、解析したデータからマーケティングに役立つデータ分析なども検索システムと連動することで実現できます。
登記簿謄本周りの事務作業の業務効率化や、謄本のデータから高度な分析が実現できます。お客様毎の業務スキームにあわせた、独自のカスタマイズを提案させて頂きます。 - 検索システム
導入サービス 
-
ポータルサイトや検索サイトだけでなく、企業の基幹システムから公共性の高いキオスク・システムまで、いまや不可欠な存在になっている検索システムを導入いたします。
お客様のご予算に応じて、弊社検索システムのパッケージソフト「Sigma Archive」を利用し安価なサービスの提供やお客様独自のカスタマイズシステムなどご提案させて頂きます。 - OCR入力支援
サービス 
-
当社では、お客様がOCRシステム導入をスムーズに行って頂くための支援サービスを行っております。
お客様の持っている帳票や画像などを文字データ化致します。
弊社の検索システムと連動すれば、お客様のデータの利便性が高まりますし、お客様のシステムに登録できる様に連携部分も開発致します。 - AI・ビッグデータ解析
機械学習導入支援 
-
AI(人工知能)や機械学習という言葉が昨今至るところで目に入るようになってきています。
AIを導入したいというご希望を承りますが、AIや機械学習で行わせる作業にも向き、不向きがあります。どのようにしたら実現できるか、お客様と一緒に考え支援させて頂きます。
また数千万件、億単位のデータ格納解析する専用DBを利用したシステム開発をご提案いたします。 - 動画解析システム
構築 
-
動画解析(再生、編集)システムを構築致します。
当社は某テレビ局の動画解析システムや埼玉県の動画配信システムの開発した経験があります。
動画を扱うシステムには、通常の開発とは違った動画関連スキルが必要となります。
当社が培ったノウハウを生かし開発を行います。 - クローリング
アプリ開発 
-
WEBサイトに公開されているデータを自動クロールしデータを収集するアプリの開発を行います。
動きのあるサイトやログインが必要なサイトなど、ありとあらゆるサイトをクロール致しますので、まずはご相談ください。 - WEB上で動作する
エディタ 
-
WEB上でWORDライクに文書を編集できるエディタの開発を行います。
ブラウザのプラグインなど使用せず、javascript等で罫表の編集や図の挿入なども行いますので、どのような環境にも適応可能です。 - システム
一括受託開発 
-
上流から下流工程、移行、導入教育、運用保守に至るまでトータルにサポートし、お客様の経営戦略をITを通じて強力にバックアップします。
昨今はリスクのあるシステム一括受託開発を避ける開発会社も多いですが、当社はお客様の予算を立てやすい一括受託開発にこだわり、製品を完成した喜びをお客様と分かち合います。 - アウトソーシング
サービス 
-
お客様先に常駐しながら、システムの企画、設計から開発、テスト、導入、運用・保守に至るまで、お客様の幅広いニーズにお応えし、基幹業務システムから情報系システム、モバイルシステムなど幅広く支援いたします。
AIや機械学習など、色々なパターンを試しながら開発行う様な開発も対応可能です。 - コンサルティング
サービス 
-
お客様の現状の業務をヒアリングさせて頂き、システム化の効果のある業務を洗い出しご提案させて頂きます。
当社がこれまで蓄積してきた情報システム構築の実績と経験を基に要件定義やRFP作成を支援致します。
得意分野
- 検索エンジン(Search Index)導入WEBシステムの構築+Suggestion機能、ファセット・ドリルダウン機能、レコメンド機能、クローラ機能搭載サービスの提供
- MAC/WINDOWS 映像解析(動画再生・編集機能)
- 多言語間連携(ZEND.JNI)
- RDB・インデックス連携(高速データフィード)
- 活字素材管理・映像素材管理
- ネット通販・ショッピングカートシステム
- 施設&資産予約管理(会議室・レンタル品)
- 物流・受注・直販システム構築
- インフラ・ネットワーク構築
開発方針
-



 お客様のご満足実現
お客様のご満足実現当社の開発方針の中核です。さまざまな大手クライアント様とのお取引を通して培った ノウハウを駆使しながら、お客様のご要望に対してトータルな提案が可能です。
-



 ご要望の実現力
ご要望の実現力特定の言語や環境にかたよらない開発体制も特長。お客様のご要望実現と目的達成の手段として技術を使い分け、真にニーズに応じたシステムの提供を実現しています。
-



 人材を通した品質維持
人材を通した品質維持スタッフの人材育成を通して、品質の維持向上やスケジュール管理などを徹底。一人ひとりの“スタッフ力”の底上げをはかることで、お客様のご満足につなげます。


Python, Watson, Zinrai, ChatBot(チャットボット), Data Mining(データマイニング), HANA, Hadoop, Tableau, HTML5, Linux, Windows, Interstage, Lucene solr, BizSearch, Shunsaku, Pana Search, FAST, Oracle, Symfoware, PostGreSQL, SQL Server, MySQL, Plain C, C++, C#, Java Servret, Java Script, Java Applet, JSP, ASP, CGI, VBA, .NET, PHP,Perl, Deliphi, Power COBOL, Assembler, Tomcat, Apache, Struts, JSON, XSUB, Zend, JNI, Q't Frame Work, Mac OSX(Snow leopard / Lion / Mountain Lion), XCODE, ObjectiveC, Spring Framework, Lotus Notes/Domino, AJAX, DOM, SAX, REST, SOAP, SAP
私たちの強み
-
 ハイレベルな検索技術のご提供
ハイレベルな検索技術のご提供
検索ニーズの高まり
ポータルサイトや検索サイトだけでなく、企業の基幹システムから公共性の高いキオスク・システムまで、いまや不可欠な存在になっている検索技術。ニーズの増加にともなって、検索に求めるレベルも高度化しています。
20年のノウハウを駆使してお客様の最適を提案
検索技術は、当社の得意分野のひとつ。いまや20年以上のキャリアがあります。
その経験とノウハウをもとに、コスト面に配慮した柔軟なご提案から開発まで、お客様のニーズにあわせて、検索システムの"トータルコーディネート"を提供しています。
-
 提案・設計・開発・構築をトータルでご提案
提案・設計・開発・構築をトータルでご提案
当社のノウハウにある"数ある選択肢"の中から選び、お客様にふさわしいシステムを組み立てていきます。
お客様は何を求めているか
〈用途とニーズ〉お客様からのヒヤリングを通して事細かに把握。当社からの提案を重ねながら、お客様とともに固めていきます。


どのように満足いただくか
〈分析と提案〉お客様の求めているのものを詳細に分析。当社の技術をどのように組み合わせれば理想に近づくのかを追求します。


開発事例紹介
開発事例の一部を紹介いたします
開発提案例
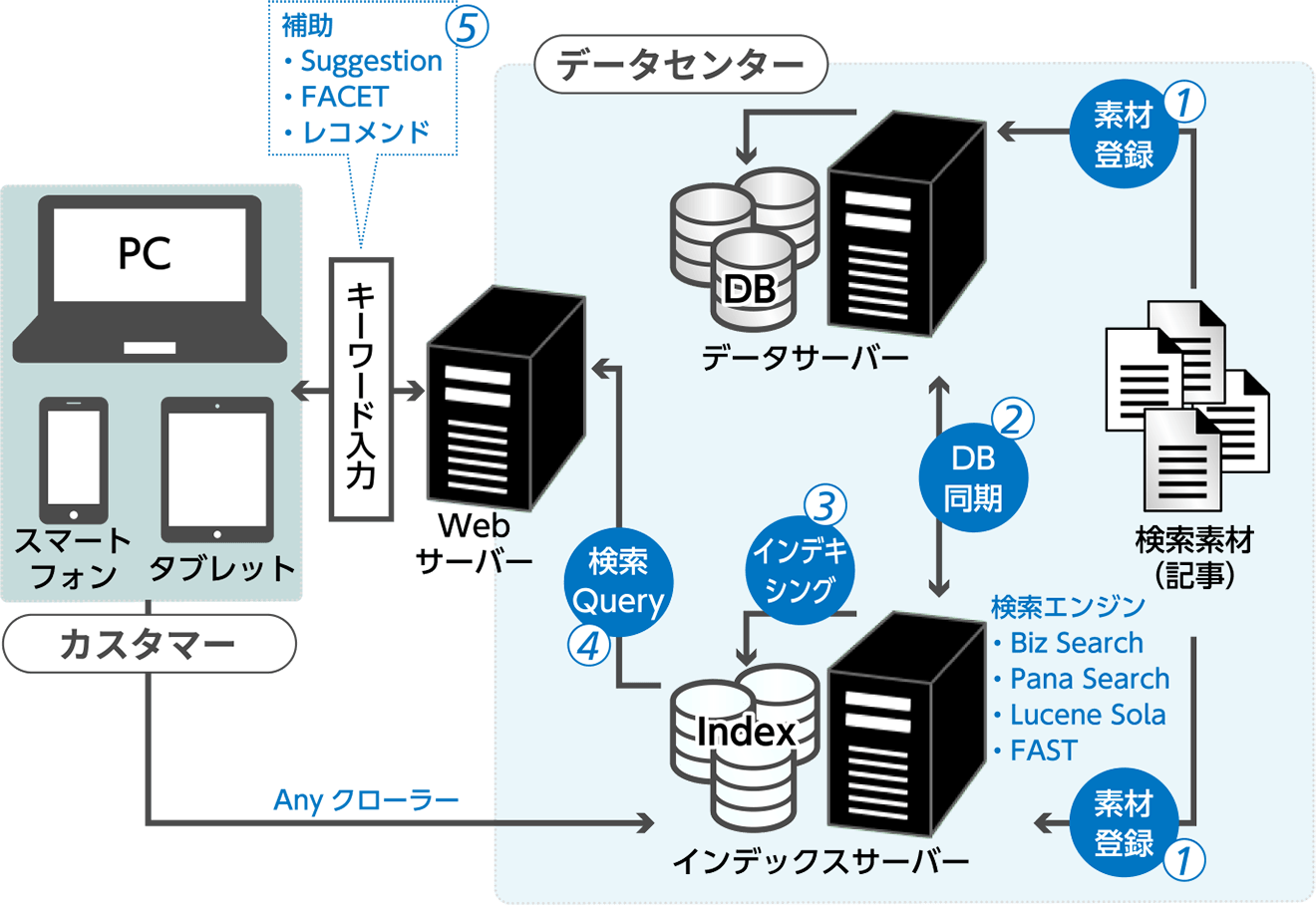
SIGMA独自の技術ノウハウ
- ①検索素材登録
- ②RDB-インデックス同期(リアルタイム同期)
- ③インデキシング(形態素解析・n-gram解析)
- ④検索Query(共通化ラッピング)
- ⑤入力補助機能(Suggestion/ファセット・ドリルダウン検索/レコメンド機能)
当社の数ある選択肢
【インデックス技術の使い分け】
- ■n-gram
- 「n」文字分ごとに文字列を区切って検索する方法。検索漏れがないことや辞書を必要としないことが特長です。
- ■形態素解析
- 単語を切り出して、その品詞を辞書と照らし合わせる方法。日本語の活用に左右されない検索が可能になります。
【検索エンジンの使い分け】
- ■Lucene Solr
- OSSであることが大きな特長。Version4となり機能拡張され、広くポータルサイトに用いられています。形態素・n-gramを選択でき、インデキシング時間も他製品より圧倒的に早いです。
- ■BizSearch
- 世界最速レベルの検索速度をうたうエンジン。Lotus Notes/DominoやSharePoint/Exchangeに対応しています。(アクセラテクノロジ株式会社様)
- ■Pana Search
- データベースとの連携を効率的に行い、ECサイトや新聞記事、特許情報のコンテンツ検索などで実績があります。(パナソニック株式会社様)
- ■FAST
- 一般のテキストベースの検索とは一味違ったノウハウが込められているエンジン。柔軟な検索を可能にしています。 (FAST, A Microsoft(R) Subsidiary様)
開発の一例
| 富士通株式会社様 |
「BizSearch」の前身であります、「ISearch」のβ版からシステム組込みの実戦サポートをさせていただいております。 さらに、新聞社様向け「記事検索システム」では、コストパフォーマンスの高い「Lucene Solr」の導入を協業し実績をあげております。 |
| 新聞記事検索 |
インターネットを通じて、記事・紙面・写真検索を実現するアーカイブシステムを多数導入いただいております。 ・山形新聞社様 ・上毛新聞社様 ・岐阜新聞社様 その他多数 |
| 開発実績 |
【公共団体】 官公庁様・自治体様向け業務システムなど 【メディア向け】 新聞サイト大手「記事検索システム」 TV局向け「映像素材編集システム」 雑誌系「素材検索システム」 就職サイト大手「学生・企業検索システム」 医薬品事業「社内文献検索システム」 旅行業「ツアー検索システム」など 【流通・販売】 販売業「商品販売ショッピングカートシステム」 販売業「販売在庫管理システム」 会計業「経理給与システム」 医薬品販売業「POSシステム」など 【産業】 総合エネルギー事業「基幹業務システム」 総合エネルギー事業「商品管理システム」など 【システム】 金融系「顧客情報管理システム」 不動産資産・物品資産「施設物品管理システム」 メーカー系「SCM(サプライチェーンマネジメント)システム」など |


 マニュアルデータからFAQデータ生成の研究(技術支援)事例
マニュアルデータからFAQデータ生成の研究(技術支援)事例

チャットボットを導入する際に、チャットボットに与えるデータ(質問文と、何を回答するべきかの文)が必要となります。
コンタクトセンターをお客様と想定し、保有しているマニュアルからFAQ(質問文と回答文)を生成する研究(技術支援)に携わった事例をご紹介します。

-
STEP01:目標の設定
マニュアルを回答として、ディープラーニング(RNN、LSTM)を用いて質問文を生成します。 -
STEP02:質問文と回答文の抽出
一般公開されているFAQサイトをクローリングしてHTMLを取得します。
取得したHTMLからテキスト化(タグ除去など)して質問文と回答文のペアを抽出します。 -
STEP03:質問文生成モデルの作成
一般公開されているFAQサイトをクローリング(スクレイピング)して質問文と回答文のペアを抽出します。
質問文と回答文のペアを教師データとしてディープラーニング(RNN、LSTM)で学習させ、質問文生成モデルを作成します。 -
STEP04:質問文生成モデルの評価
質問文生成モデルに対して、学習時の回答文や任意の回答文を与えることで質問文を生成します。
生成された質問文が質問文生成モデルに与えた回答文とペアとして成り立つかを評価します。
成り立たない場合、データ(量・質)を見直すなどして、質問文生成モデルの作成~評価を繰り返します。 -
STEP05:マニュアルからFAQの生成
マニュアルから回答文となる文章を抽出します。
質問文生成モデルに対して、マニュアルから抽出した回答文を与えることで質問文を生成します。
生成された質問文とモデルに与えた回答文がペアとして成り立つかを評価します。
成り立たない場合、データ(量・質)を見直すなどして、質問文生成モデルの作成からやり直します。
 紙媒体のデータを既存システムへデータ登録する事例
紙媒体のデータを既存システムへデータ登録する事例

大手出版社の自治体向け条例システムの開発に携わった例を紹介します。
画像処理を伴う電子化文書技術を活用し、紙媒体の文書ファイルを電子化、検索可能とするシステムになります。
取込精度をどこまで上げられるかが本開発のポイントとなります。

-
STEP01:現状分析
自治体向け条例システムを使用する為には、自治体様が持っているデータを登録する必要がありますが、紙媒体で管理している自治体様の場合、登録作業に多大な労力が掛かっておりました。
その作業をなんとか自動化できないかと検討を始めます。 -
STEP02:OCR製品選定
紙媒体の文書ファイルをシステムに取り込む為には、OCR技術を使用します。OCR製品は様々な製品が出ており、それぞれ一長一短ありますので、今回のシステムにはどの製品があうかを選定します。
それぞれの製品を使用してみて文字認識率を算出し選定していきます。 -
STEP03:課題洗い出し
人が登録すると当たり前の様にできている事が、システムで行うには難しい場合があります。
本を取り込む場合、上部に「〇章 総則」の様な見出しが毎ページに出てきたり、下部にページ番号が出てきたり原稿にパンチの穴があったりします。
人が登録する場合、本文のみを入力したいので、見出しやページ番号やパンチの穴を区別する事は簡単ですが、システムで行う為には工夫が必要です。 -
STEP04:パターン認識により解決
機械学習のライブラリを使用し、画像パターンを認識させて、見出しやページ番号パンチの穴、画像、罫表などを区別し登録します。また文字のかたまりがOCRに分かる様に画像に印を付けてあげたりし、文字認識の精度率の向上を行います。
OCRではスキャン画像の前処理で補正する事が精度率を大きく左右します。 -
STEP05:さまざまなシステムへ応用
認識精度の高いOCR技術はさまざまなシステムへの応用が可能になります。
今回は編集系システム、検索系システムへの登録を行っております。